
In previous articles, we introduced the overall architecture of Alibaba Cloud’s Tongyi family and its core language model, Qwen, highlighting its critical role in text understanding, reasoning, and enterprise applications. However, generative AI extends far beyond text. As businesses increasingly demand high-quality images, videos, and multimedia content, the ability of AI to effectively understand and generate visual content has become the next crucial frontier.
The Creative Sensory System of the Family: From Text to Vision
If Qwen (Tongyi Qianwen) serves as the “rational brain” of the Tongyi family—handling text comprehension, logical reasoning, and decision support—then Tongyi Wan acts as its “creative sensory system,” endowing AI with the ability to understand and generate visual content.
When it comes to highly contextual and expressive media like images and videos, AI must do more than just recognize objects—it must grasp semantic meaning, relational context, and creative intent. Tongyi Wan is built precisely for this purpose: extending generative AI from language into the visual domain, so AI doesn’t just see but truly creates.
This shift transforms AI from a passive analytical tool into an active participant in enterprise content creation—becoming a foundational engine for image, video, and multimedia innovation. It marks the evolution of the Tongyi family from pure understanding and reasoning toward full-spectrum multimodal generation.
Three Core Capabilities for Visual Content Creation
For enterprises, the true value of AI-powered visual generation lies in solving real-world content production challenges—from initial asset creation to iterative optimization. Common pain points include:
- Rapidly generating multiple versions of marketing visuals
- Adapting existing images to align with a campaign’s master visual identity
- Swapping products or text while maintaining consistent style and tone
- Transforming static images into dynamic, engaging motion content
Tongyi Wan is purpose-built to address these needs, structured around three core capabilities:
- Image Generation – Create high-quality, on-brand visual assets quickly and easily, lowering the barrier to professional-grade content creation.
- Image Editing – Enable precise, iterative refinements—such as object replacement, style transfer, or layout adjustments—while preserving visual coherence.
- Video Generation – Bring static visuals to life with motion, enabling richer storytelling and expanding use cases across digital ads, social media, and e-commerce.
The following sections detail each capability and its enterprise applications.
Image Generation: Beyond Imagination, Toward Precision Design
Tongyi Wan’s image generation capability transforms textual prompts or visual concepts into professional-grade, production-ready images, enabling enterprises to create usable visual assets right from the early stages of content development. For example, an advertising agency can instantly generate concept visuals for a brand campaign—helping clients grasp creative ideas immediately, without waiting days for traditional design iterations or incurring high production costs.
Key Features
- High-Fidelity Prompt Understanding
Accurately interprets nuanced instructions—including scene context, composition, and artistic style—and converts abstract descriptions into precise, on-brand visuals. This minimizes the need for repeated prompt tweaking and accelerates time-to-output. - Professional Visual Quality Across Styles
Delivers exceptional realism in lighting, texture, and depth—producing images that rival real photography—while also supporting diverse artistic styles, from minimalist to illustrative, tailored to brand guidelines. - High-Efficiency, Multi-Variant Output
Rapidly generates multiple versions of visuals in a single workflow, including integrated text-and-image layouts, infographics, and branded templates—empowering teams to scale content creation and refresh campaigns faster than ever.
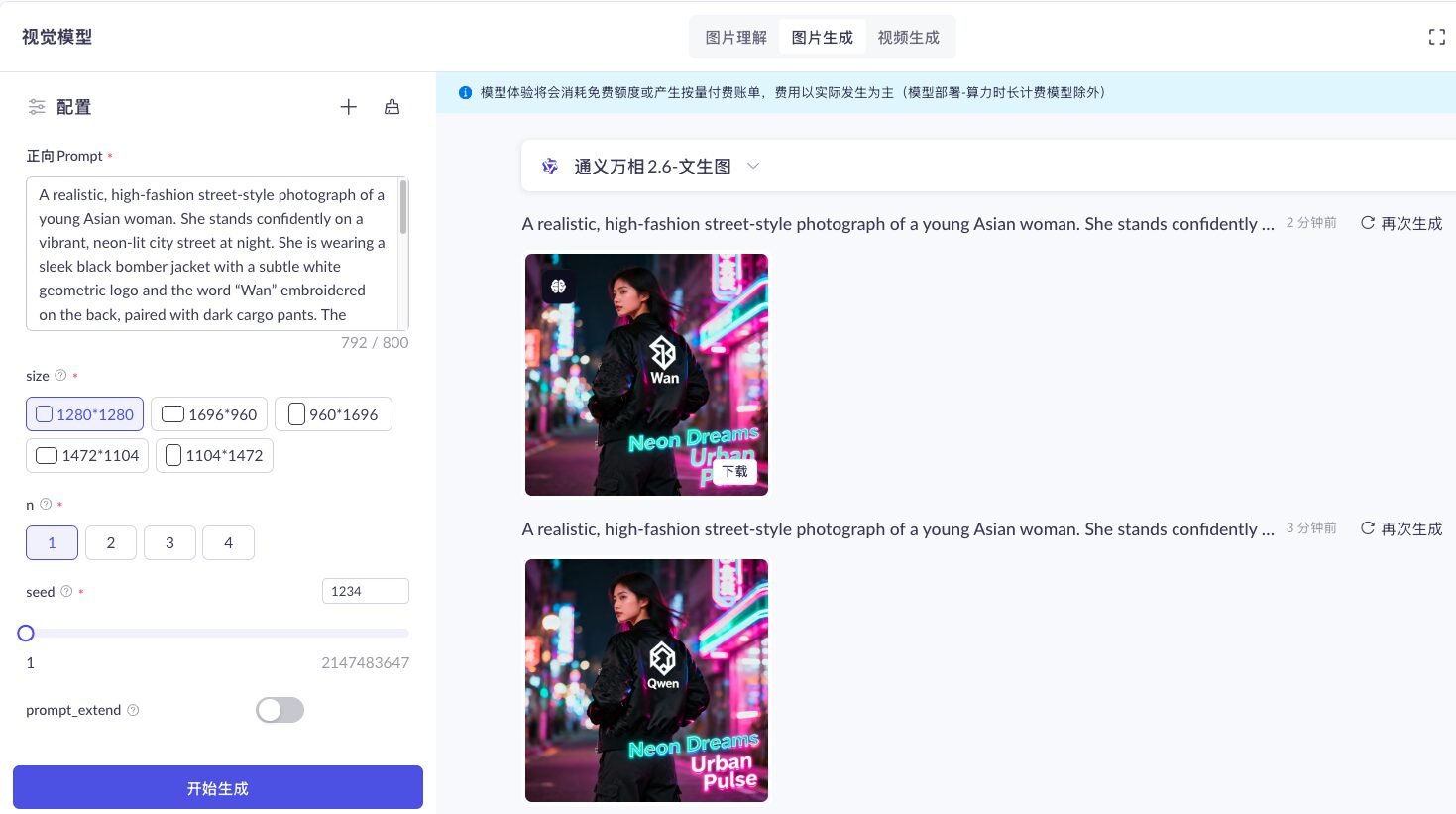
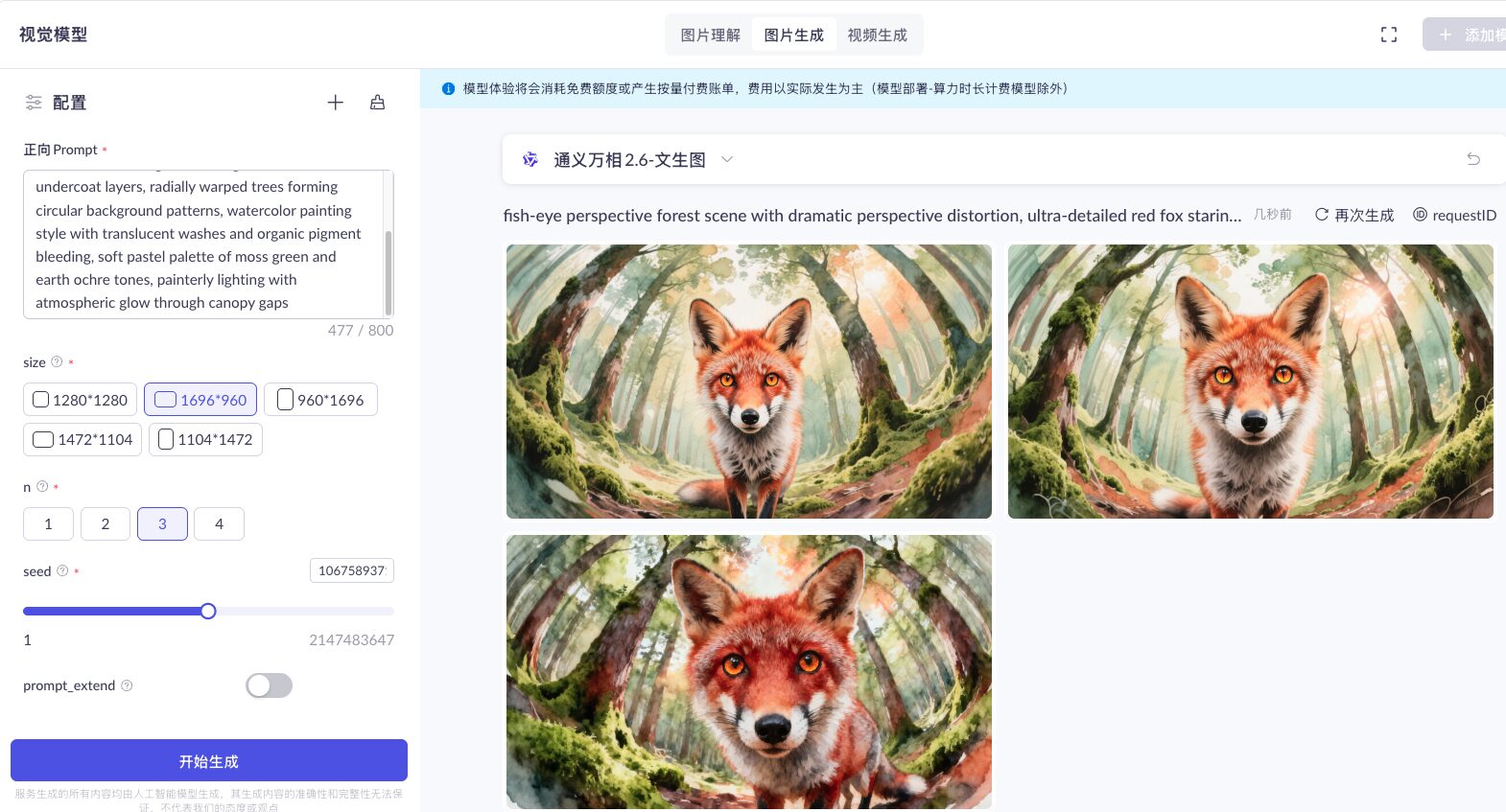
Image Editing: Seamless Style Switching with Precision
Tongyi Wan’s image editing capability empowers enterprises to refine and repurpose existing visuals—without starting from scratch. Instead of reshooting or redesigning, teams can use AI to make precise, context-aware adjustments, turning Tongyi Wan into a collaborative content creation partner.
For example, during festive seasons, e-commerce teams often need to rapidly produce themed marketing assets. With Tongyi Wan, they can simply provide a high-quality product photo—like a bottle of barbecue sauce—and use a natural-language prompt such as: “Place this barbecue sauce in a lively riverside BBQ scene with a group of friends.” In seconds, a ready-to-use promotional image is generated—no photoshoot required.
Key Features
- Conversational Editing for Iterative Refinement
Modify images using intuitive, natural-language instructions. Support for multiple rounds of edits and fine-tuning drastically reduces time and cost compared to traditional rework cycles. - Pixel-Level Precision for Professional Retouching
Edit specific regions of an image—swap backgrounds, adjust lighting, or replace objects—while maintaining photorealistic quality. Ideal for product shots, ad creatives, and design workflows. - Multi-Reference Consistency Control
Upload up to 4 reference images to guide style, character appearance, or visual tone. This ensures consistent branding and visual coherence across campaigns, even when generating multiple variants.
The following demonstrates using Tongyi Wan to generate a new image by combining two images and editing photo details.
Step 1: Provide a precise prompt – “Please combine the two images: use the second image, which features flowers and sunlight, as the background. Integrate the blue umbrella-holding sprite from the first image into the second image, and change the sprite’s expression to a smile. Apply the color tone of the second image as the overall style.”

Step 2: Done

Video Generation: Synchronized Audio-Visual Content with Premium Quality
Tongyi Wan’s video generation capability supports multiple input types—including text, images, and audio—enabling enterprises to intuitively create dynamic, stylistically consistent videos for marketing, product showcases, and multimedia communication.
Traditionally, producing a short promotional video for a single product involves scripting, voice recording, shooting or designing assets, and editing—a complex, time-consuming process. Scaling this across dozens of languages and regional cultural styles multiplies cost and timeline pressures. Tongyi Wan addresses these challenges by enabling intuitive, efficient, and scalable video production, breaking through content creation bottlenecks and supporting both mass customization and localization.
Key Features
- Multimodal Input for Flexible Creation
Generate videos from text prompts, animate still images into motion, or sync custom audio tracks—all within a unified workflow. This eliminates dependency on a single asset type and accelerates production. - Synchronized Audio-Visual Output
Automatically aligns narration or voiceovers with visual pacing, creating natural, engaging videos ideal for product demos, tutorials, and promotional content. - Cinematic-Quality Consistency
Delivers high-resolution videos with stable motion, coherent scene structure, and consistent character/style rendering—meeting enterprise-grade standards for professional visual storytelling.
The following demonstrates Tongyi Wan generating a high-quality animated advertisement using only a text prompt.
Step 1: Create a cute animation with text-to-video
Prompt: “A cute animated hippo is making coffee in a modern office. The hippo has a soft, rounded body, big eyes, and a warm smile, wearing casual yet work-appropriate clothing (e.g., a checkered shirt or knit vest). The setting is a bright, warm office environment.”

Step 2: Generate a high-quality video and refine it via the sidebar controls—adjusting resolution, frame size, video duration, random seed, camera angle, and audio generation to enhance completeness and production value.
Smart Expansion: When enabled, the large model automatically rewrites and enriches the original prompt to compensate for brevity or ambiguity, significantly improving output quality.
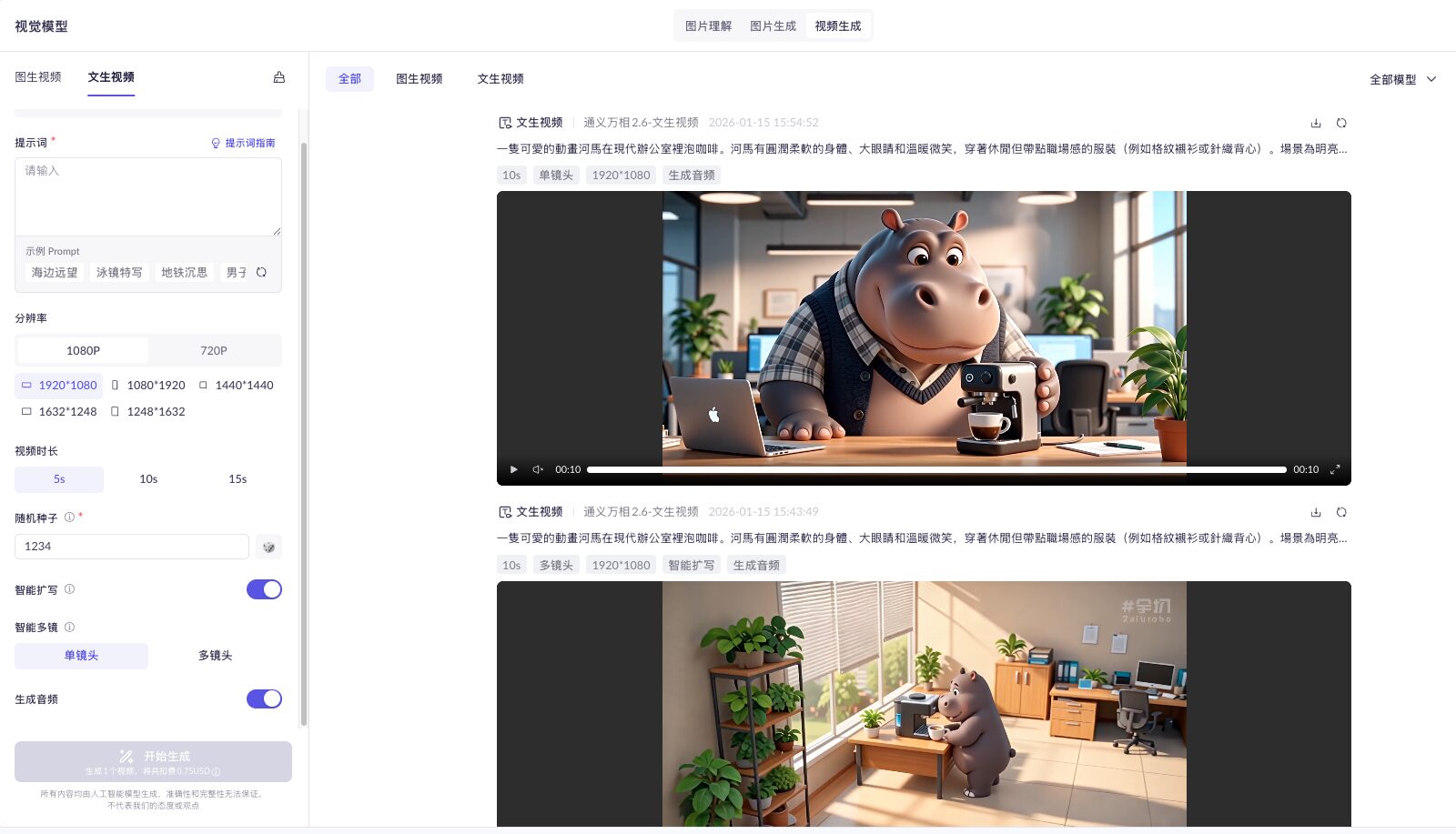
Step 3: Final Output Showcase
Evolution of Tongyi Wan: Core Enhancements in Wan 2.6
In late 2025, Alibaba Cloud officially launched Tongyi Wan 2.6, marking a significant leap from early-stage visual generation toward a mature, production-ready system. While earlier versions prioritized visual appeal, Wan 2.6 focuses on stability, consistency, and real-world usability—directly addressing enterprise pain points in image editing, asset creation, and video production workflows.
Key Enhancements in Wan 2.6
Built on a next-generation model architecture, Wan 2.6 significantly advances video generation with a focus on reference fidelity, audio-visual integration, and narrative coherence:
- Multimodal Reference-Based Video Generation
Accepts text, images, audio, or short video clips as references to accurately replicate the appearance, motion, and voice characteristics of characters, animals, or objects—ensuring high visual and auditory consistency throughout the generated video. - Native Audio-Visual Synchronization
Delivers tightly synchronized sound and visuals, supporting multi-character dialogue, voiceovers, and background music. This results in natural pacing, emotional resonance, and a cinematic viewing experience. - Intelligent Multi-Shot Storytelling
Understands natural language or director-style shot instructions (e.g., “close-up,” “pan left”) to automatically generate coherent sequences with multiple camera angles—maintaining character identity, artistic style, and narrative continuity without manual editing. - High-Quality Long-Form Video Output
Supports 15-second 1080p videos with enhanced detail, smoother motion, and refined artistic quality—making it suitable for professional marketing campaigns, brand storytelling, and commercial-grade multimedia content.
Key Differences Between Wan 2.5 and Wan 2.6
|
Feature
|
Wan 2.5
|
Wan 2.6
|
|---|---|---|
|
Reference Video Support
|
Limited
|
Supports full-length reference videos; maintains character appearance and voice consistency
|
|
Multi-Character Interaction
|
Less stable
|
Stable support for multi-character interaction and performance
|
|
Audio-Visual Synchronization
|
Basic
|
Natural, realistic audio-video synchronization
|
|
Audio Quality
|
Standard
|
Significantly improved realism and music quality
|
|
Multi-Shot Narrative Ability
|
Limited
|
Intelligent shot sequencing with consistent storytelling
|
|
Prompt Following Capability
|
Moderate
|
Stronger and more precise prompt adherence
|
|
Max Video Length
|
10 seconds
|
15 seconds
|
|
Video Resolution Options
|
480p, 720p, 1080p
|
720p, 1080p
|
Tongyi Wan: Expanding the Enterprise AI Visual Experience
Tongyi Wan is not just a single model or isolated feature—it’s a comprehensive visual generation system encompassing image creation, image editing, and video generation. Through continuous model evolution and capability integration, it is transforming generative AI from a creative assistant into a core technology that powers real enterprise content workflows.
With the release of Wan 2.6, Tongyi Wan has reached new levels of maturity in stability, visual consistency, and audio-visual quality, demonstrating its readiness for real-world business applications. Enterprises can now confidently adopt AI-powered visual generation across marketing, branding, multimedia content, and internal communications—with reliable, scalable, and on-brand results.
As an Alibaba Cloud Professional Partner, Microfusion brings deep expertise in Alibaba Cloud solutions. We provide end-to-end support—from needs assessment and technical planning to environment deployment—ensuring your project benefits from the highest quality implementation, maintenance, and innovation enablement.
Contact us today for expert consultation on Tongyi Wan.


