
從零售到遊戲,從程式碼生成到客戶服務,越來越多的組織正在運行基於大型語言模型 (LLM) 的應用程式,目前 78% 的組織正處於開發或生產階段。隨著生成式 AI 應用程式的數量和用戶規模不斷擴大,對高效能、可擴展且易於使用的推論技術需求變得至關重要。Google Cloud 正透過 AI Hypercomputer 為 AI 快速演進的下一階段鋪平道路。
在 Google Cloud Next ’25 大會上,Google 分享了許多關於 AI Hypercomputer 推論能力的更新,展示了 Ironwood,這是專為推論設計的最新 Tensor Processing Unit (TPU)。此硬體更新搭配了軟體增強功能,例如使用 vLLM on TPU 進行簡單高效的推論,以及最新的 GKE 推論功能——GKE Inference Gateway 和 GKE Inference Quickstart。透過 AI Hypercomputer,持續透過最佳化軟體推升效能,並有強大的基準測試支持:
- Google 的 JetStream 推論引擎結合了新的效能最佳化,整合了 Pathways 以實現超低延遲的多主機、解離服務(disaggregated serving)。
- MaxDiffusion 是 Google 潛在擴散模型的參考實作,在 TPU 上為計算密集型圖像生成工作負載提供了卓越的效能,現在支援 Flux,這是迄今為止最大的文字轉圖像生成模型之一。
- MLPerf™ Inference v5.0 的最新效能結果展示了 Google Cloud 的 A3 Ultra (NVIDIA H200) 和 A4 (NVIDIA HGX B200) VM 在推論方面的強大功能和多功能性。
目錄
目錄
最佳化 JetStream 效能:Google 的 JAX 推論引擎
為了最大限度地提高效能並降低推論成本,Google 很高興能在 TPU 上服務 LLM 時提供更多選擇,進一步增強 JetStream 並為 TPU 帶來 vLLM 支援,這是一個廣泛採用且高效的 LLM 服務庫。透過 TPU 上的 vLLM 和 JetStream,以開源貢獻和 Google AI 專家的社群支援,提供低延遲、高吞吐量的推論,實現卓越的性價比。
JetStream 是 Google 的開源、吞吐量和記憶體最佳化推論引擎,專為 TPU 而建,並基於用於服務 Gemini 模型的相同推論堆疊。自去年四月Google 宣布 JetStream 以來,Google 已投入大量資源進一步提升其在各種開源模型上的效能。使用 JetStream 時,Google 的第六代 Trillium TPU 現在在 Llama 2 70B 上的吞吐量效能比 TPU v5e 高出 2.9 倍,在 Mixtral 8x7B 上的吞吐量效能比 TPU v5e 高出 2.8 倍(使用Google 的參考實作 MaxText)。
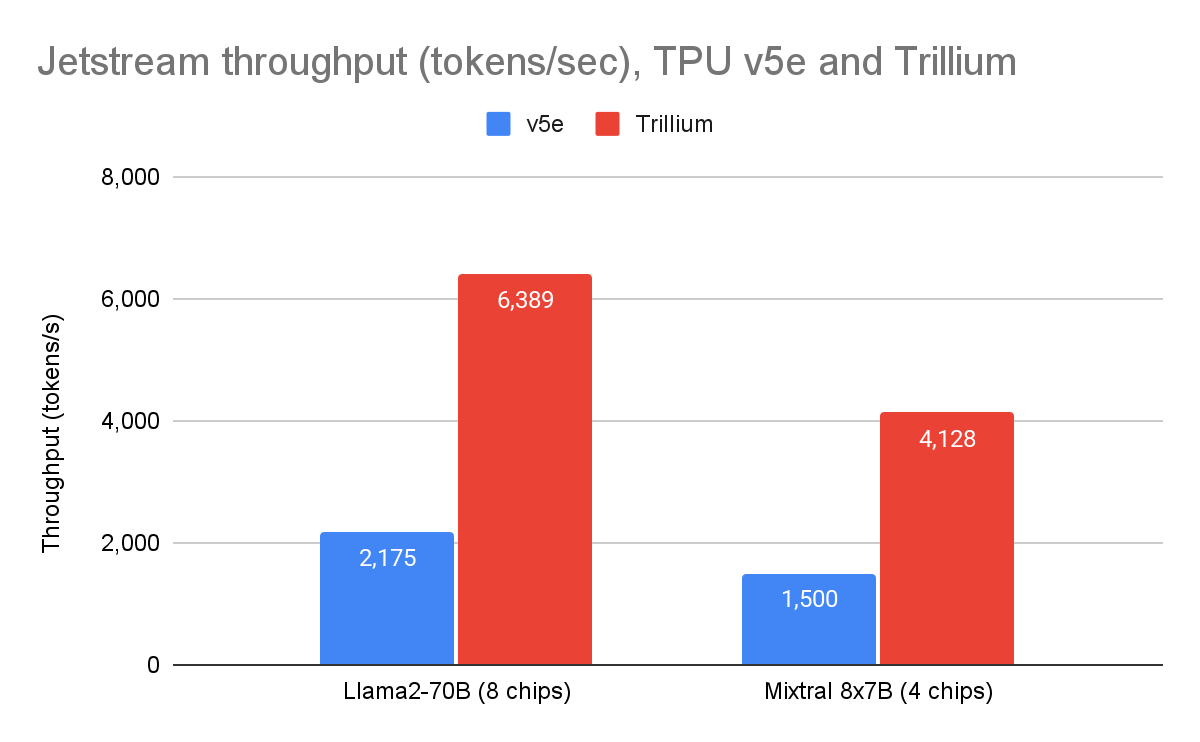
圖 1:JetStream 吞吐量(每秒輸出 tokens)。 Google 內部數據。使用 Cloud TPU v5e-8 和 Trillium 8 晶片上的 Llama2-70B (MaxText) 以及 Cloud TPU v5e-4 和 Trillium 4 晶片上的 Mixtral 8x7B (MaxText) 測量。最大輸入長度:1024,最大輸出長度:1024。截至 2025 年 4 月。
Google 的 Pathways 運行時首次向 Google Cloud 客戶開放,現已整合到 JetStream 中,實現了多主機推論和解離服務(disaggregated serving)——這兩個重要功能隨著模型規模呈指數級增長和生成式 AI 需求演變而變得越來越重要。
使用 Pathways 的多主機推論在服務時將模型分佈到多個加速器主機。這使得無法在單一主機上容納的大型模型能夠進行推論。透過多主機推論,JetStream 在 Trillium 上的 Llama 3.1 405B 上實現了 1703 token/s 的速度。這意味著每美元的推論量是 TPU v5e 的 三倍。
此外,藉助 Pathways,解離服務功能允許工作負載獨立地動態擴展 LLM 推論的解碼和預填充階段。這有助於更好地利用資源,並能提高效能和效率,特別是對於大型模型。對於 Llama2-70B,使用多個主機進行解離服務,預填充(首次 tokens 時間,TTFT)操作的效能提高了七倍,而 tokens 生成(每個輸出tokens時間,TPOT)的效能則幾乎提高了三倍,相較於在 Trillium 上同一伺服器上交錯處理 LLM 請求的預填充和解碼階段。


圖 2:使用 Cloud TPU Trillium 16 晶片(8 晶片分配給預填充伺服器,8 晶片分配給解碼伺服器)上的 Llama2-70B (MaxText) 測量。 使用 OpenOrca 數據集測量。最大輸入長度:1024,最大輸出長度:1024。截至 2025 年 4 月。
MaxDiffusion:高效能擴散模型推論
除了大型語言模型(LLM)之外,Trillium 在圖像生成等計算密集型工作負載上也展現了卓越的效能。MaxDiffusion 提供了一系列潛在擴散模型的參考實作。除了 Stable Diffusion 推論之外,Google 還擴展了 MaxDiffusion,現在支援 Flux;Flux 擁有 120 億個參數,是迄今為止最大的開源文字轉圖像模型之一。
正如 MLPerf 5.0 所展示的,Trillium 現在在 Stable Diffusion XL (SDXL) 上每秒查詢數的吞吐量比其前身 TPU v5e 的上一輪效能提高了 3.5 倍。自 MLPerf 4.1 提交以來,這進一步將吞吐量提高了 12%。

圖 3:MaxDiffusion 吞吐量(每秒圖像數)。 Google 內部數據。使用 Cloud TPU v5e-4 和 Trillium 4 晶片上的 SDXL 模型測量。解析度:1024×1024,每設備批次大小:16,解碼步驟:20。截至 2025 年 4 月。
憑藉這種吞吐量,MaxDiffusion 提供了一個經濟高效的解決方案。在 Trillium 上生成 1000 張圖像的成本低至 22 美分,比 TPU v5e 降低了 35%。

圖 4:生成 1000 張圖像的擴散成本。 Google 內部數據。使用 Cloud TPU v5e-4 和 Cloud TPU Trillium 4 晶片上的 SDXL 模型測量。解析度:1024×1024,每設備批次大小:2,解碼步驟:4。成本基於美國 Cloud TPU v5e-4 和 Cloud TPU Trillium 4 晶片的 3 年 CUD 價格。截至 2025 年 4 月。
A3 Ultra 和 A4 VM MLPerf 5.0 推論結果
對於 MLPerf™ Inference v5.0,Google Cloud 提交了 15 項結果,包括首次提交的 A3 Ultra (NVIDIA H200) 和 A4 (NVIDIA HGX B200) VM。A3 Ultra VM 由八個 NVIDIA H200 Tensor Core GPU 提供支援,提供 3.2 Tbps 的 GPU 對 GPU 無阻塞網路頻寬,以及比搭載 NVIDIA H100 GPU 的 A3 Mega 多兩倍的高頻寬記憶體 (HBM)。Google Cloud 的 A3 Ultra 展現出極具競爭力的效能,在 LLM、MoE、圖像和推薦模型方面取得了與 NVIDIA 峰值 GPU 提交結果相當的成績。
Google Cloud 是唯一在 NVIDIA HGX B200 GPU 上提交結果的雲端供應商,展示了 A4 VM 在服務 LLM(包括 Llama 3.1 405B,這是 MLPerf 5.0 中引入的新基準)方面的卓越效能。A3 Ultra 和 A4 VM 都提供強大的推論效能,證明了Google 與 NVIDIA 的深度合作,為最苛刻的 AI 工作負載提供基礎設施。
AI Hypercomputer 正在推動 AI 推論時代
Google 在 AI 推論方面的創新,包括 Google Cloud TPU 和 NVIDIA GPU 的硬體進步,以及 JetStream、MaxText 和 MaxDiffusion 等軟體創新,正在透過整合的軟體框架和硬體加速器推動 AI 的突破。
Google 推出了 AI Hypercomputer 超級電腦,大幅提升了雲端運算力,宏庭科技身為 Google Cloud Premier Partner 也備感榮幸!期待未來有更多 AI 相關資訊,都能由宏庭科技第一手消息,通知各位,請密切關注Google 的活動訊息,期待在活動中與您相見!若有任何問題及需求,歡迎聯繫宏庭科技。


