
在前文中,我們已經介紹了阿里雲通義家族的整體架構,以及作為核心語言模型的通義千問,說明其如何在文字理解、推理與企業應用場景中發揮關鍵角色。然而,生成式 AI 的應用並不僅止於文字。隨著企業對影像、影片與多媒體內容的需求日益增加,AI 能否有效理解並生成視覺內容,也逐漸成為下一個重要關鍵。
目錄
目錄
家族中的創意感官:從文字走向視覺
如果說通義千問扮演的是家族中的理性大腦,負責文字理解、邏輯推理與決策支援,那麼通義萬相(Wan),則更像是家族中的「創意感官」,讓 AI 開始具備理解並生成視覺內容的能力。
面對影像與影片這類高度視覺化、情境化的內容,AI 不僅需要辨識畫面中的物件與元素,更必須理解其背後的語意、關係與創作意圖。通義萬相正是以此為核心設計,將生成式 AI 的能力,從語言延伸至影像與影片,讓 AI 不只停留在看得懂,而是真正能做得出來。
這樣的能力轉變,使得 AI 得以從輔助分析工具,進一步參與企業的內容產製與創作流程,成為推動影像、影音與多媒體應用的重要基礎,也讓通義家族的整體 AI 能力,從理解與推理,走向更完整的多模態生成。
三大視覺化作業核心能力
而對企業來說,視覺生成的核心價值,在於精準解決從素材產出到優化繁瑣內容作業流程。例如,如何快速產出多版素材、如何把既有圖片改成符合活動主視覺的版本、如何替換商品或文案但保持整體風格一致,以及如何把靜態畫面延伸成更具表現力的動態內容。
通義萬相正是圍繞這些需求打造,並可歸納為三大核心方向:
1. 圖片生成——用更低門檻的方式快速產出可用的視覺化素材
2. 圖片編輯——讓素材能依修改進行反覆修改及優化
3. 影片生成——讓內容從靜態走向動態,支援更豐富的內容呈現與應用場景
以下將依此順序展開介紹。
圖片生成:突破想像,精準設計
通義萬相的圖片生成能力,可依照文字描述或視覺需求,快速產出具備實際應用價值的專業級圖片,協助企業在內容製作初期,就建立出可直接使用的視覺素材。例如:廣告公司針對品牌廣告提案時,可使用 AI 快速生成具備創意概念的圖片,快速讓品牌方理解創意概念,而非受限於傳統設計流程的冗長等待與高額成本。
重點特色
- 指令理解力高,生成結果更貼近實際需求
能準確理解指令中的情境、構圖與風格設定,將抽象描述轉化為具體畫面,減少反覆調整提示詞所需的時間與成本。 - 專業級視覺品質,兼顧寫實與多元風格表現
在光影、材質與畫面層次上具備良好表現,可產出接近實拍質感的圖片,同時支援多樣化藝術風格與品牌視覺需求。 - 高效率多樣產出,支援各式內容製作情境
能快速生成多種版本的視覺素材,包含圖文整合設計與專業圖表等內容,協助企業提升素材製作效率,加速內容更新。
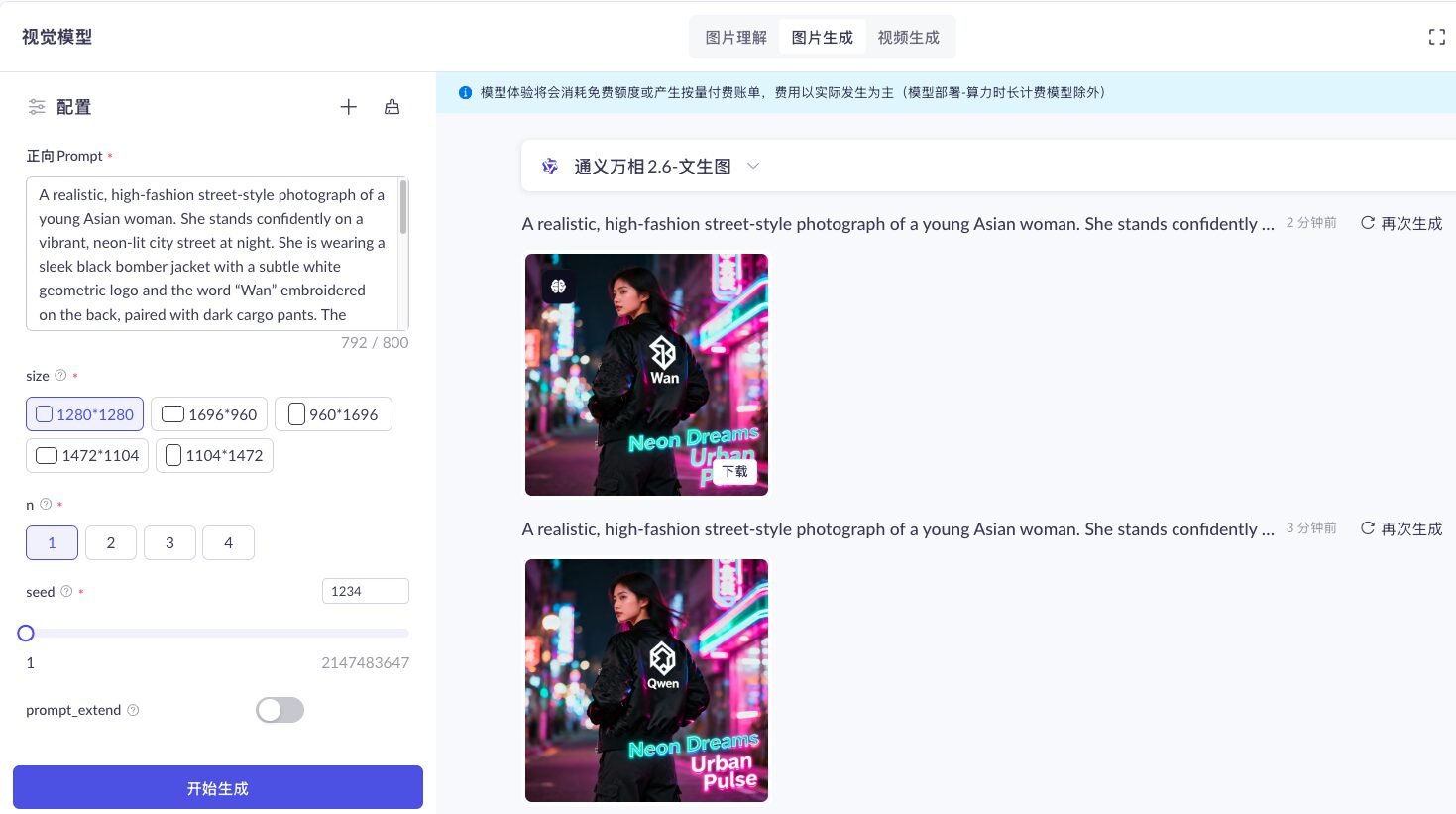
運用文字生成的具現代感的人物圖像
可調整圖片大小(size)、圖片生成數量 (n)、隨機數(seed) 生成更多樣的圖片
圖片編輯:多樣風格,精準切換
通義萬相的圖片編輯能力,讓企業不必每次都重新生成素材,而是能在既有畫面的基礎上,依實際需求進行精準調整與優化,讓 AI 成為能與團隊協作的內容製作輔助工具。在電商業者中,若遇到節慶,需大量產製相關的行銷廣告素材,此時通義萬相,可依照風格化與情境切換,避免重新拍攝,例如:端午節慶家家要買烤肉醬,那電商團隊僅需提供一高品質的產品原圖,以對話式指令編輯圖片:「請將烤肉醬放在一群朋友在河堤烤肉的熱鬧情境中」,即可得到一行銷廣告素材,無須進行拍攝。
重點特色
- 對話式指令編輯,支援精準修改與多次調整
可透過自然語言下指令調整畫面內容,支援多次修改與細節微調,減少反覆重做素材所耗費的時間與成本。 - 精準編輯,滿足專業修圖需求
能針對畫面中特定區域進行細節調整與內容修改,確保編輯結果符合專業級視覺品質,適用於產品圖片、行銷素材與設計應用。 - 多圖參考與高度一致性呈現
可上傳最多4張圖片作為參考,維持角色、風格與視覺元素的一致性,讓不同素材與版本之間,仍能維持穩定的視覺表現。
以下示範,使用通義萬相將兩張圖片的生成新圖片,並編輯照片細節。
- Step1:下精準的 prompt –「請將兩張圖片結合,背景放第二張有花及陽光的照片,將撐傘藍色小精靈融入於第二張圖片中,並將藍色小精靈的表情改為微笑。圖片色調請以第二張為主」

- Step2:完成
 影片生成:影音同步,質感升級
影片生成:影音同步,質感升級
通義萬相的影片生成能力,支援文字、圖片與聲音等多種輸入形式,讓企業能以更直覺的方式產出具備一致風格與流暢動態的影片內容,並可實際應用於行銷、展示與多媒體溝通的情境。企業在製作單一產品的短影音,需經過腳本撰寫、配音錄製、素材拍攝/設計、影片剪輯等環節,流程複雜且耗時。要同步應對多達十幾種語言和不同的地區文化風格,製作成本與時間壓力極高。然而,通義萬相的影片生成能力正是為了解決這些挑戰,讓企業能以更直覺、高效率的方式,突破內容產製的瓶頸,實現影音內容的規模化與在地化。
重點特色
- 多模態輸入,影片生成更有彈性
可根據文字描述生成影片,也能以圖片作為基礎,進一步製作成動畫效果,並可輸入音軌同步進行影片產出,讓影片製作不再受限於單一素材形式。 - 影音同步生成,強化內容表現力
支援將旁白或聲音內容與影片同步製作,呈現出自然的畫面節奏與聲音表現,適合用於產品介紹、教學說明與宣傳影片等場景。 - 電影級品質,確保穩定呈現
在動態表現與畫面結構上具備良好穩定度,可產出高解析度的影片內容,確保角色、風格與畫面氛圍的一致性,滿足企業對專業影片品質的基本需求。
以下將展示通義萬相,利用文字指令,生成一隻高品質的動畫廣告片。
- Step1:運用文字生成的可愛動畫,Prompt:「一隻可愛的動畫河馬在現代辦公室裡泡咖啡。河馬有圓潤柔軟的身體、大眼睛和溫暖的微笑,穿著休閒但帶有職場感的服裝(例如格紋襯衫或針織背心)。場景為明亮溫暖的辦公環境中」

- Step2:可依照文字產出高品質的影片,藉由側邊欄位進行解析度、畫面大小、影片時長、隨機數、鏡頭角度、音訊生成等調整,增加影片完整性
*智慧擴寫:開啟後,大模型會評估目前的Prompt進行改寫,可彌補Prompt過短而生成效果不佳的問題
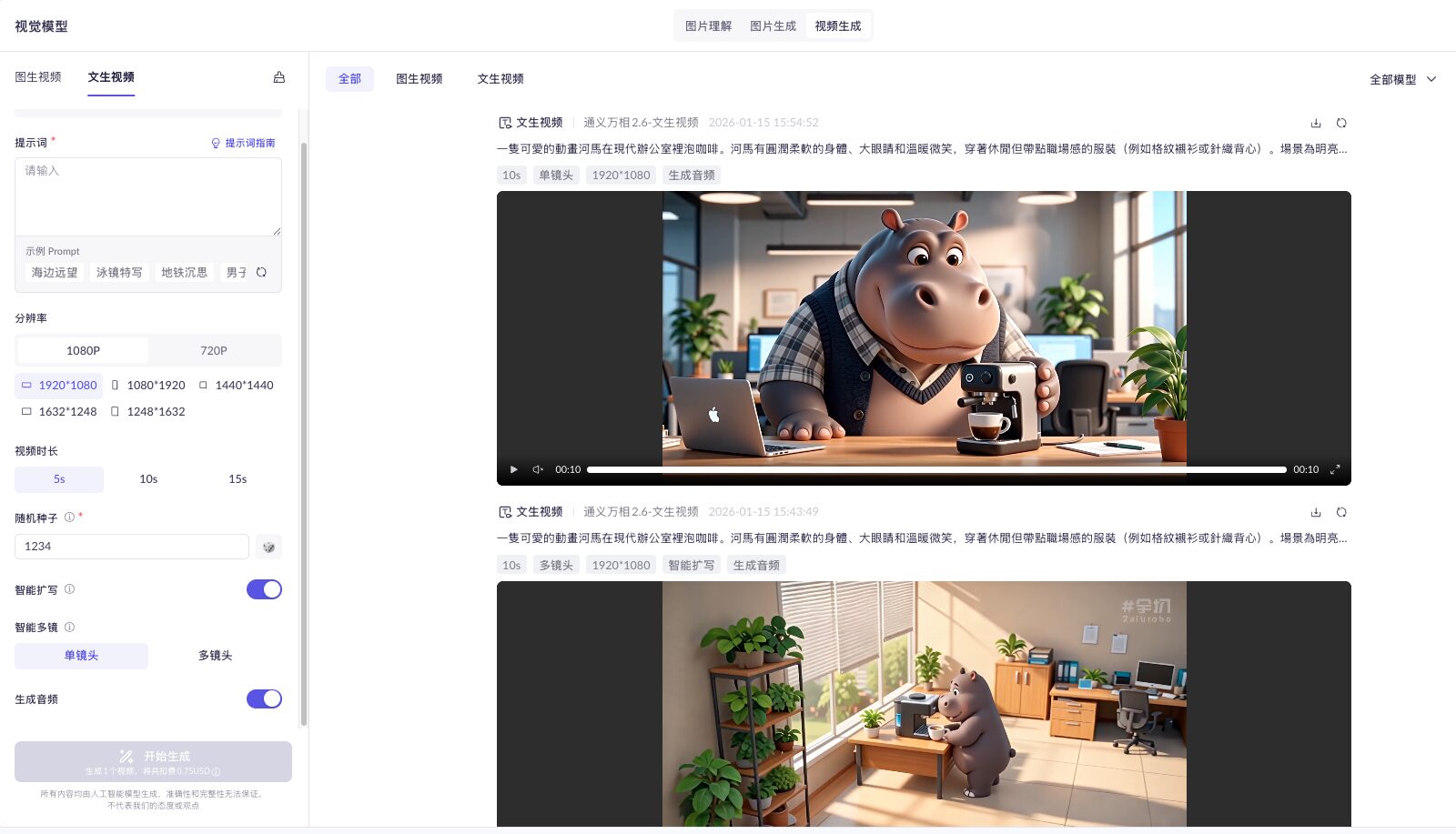
- Step3:成品展現
通義萬相的能力演進:Wan 2.6的核心強化
於 2025 年底,阿里雲正式推出最新的 Wan 2.6 版本,其視覺生成能力已從早期著重生成效果,進一步演進為更強調穩定性、一致性與實際可用性的成熟階段。隨著企業對圖片、編輯與影片等視覺應用需求日益提高,通義萬相也持續針對內容製作流程中的實務痛點進行優化,使 AI 生成結果能更順利地被納入實際工作流程中使用。
Wan 2.6 的關鍵特色
基於最新一代模型架構,Wan 2.6 在影片生成能力上,聚焦於參考一致性、音畫整合與敘事表現等關鍵面向,以下為其核心強化重點:
- 多模態參考影片生成
支援文字、圖片與音訊等多種輸入形式,並可透過短影片或角色參考,準確複製人物、動物或物件的外觀與聲音特徵,確保影片在生成過程中維持高度一致的視覺與聲音表現。 - 原生影音同步產出
強化聲音與畫面的同步能力,支援多角色對話、旁白與音樂表現,使影片在敘事節奏、聲音質感與畫面動態上更加自然一致,提升整體觀賞體驗。 - 智慧多鏡頭敘事能力
能理解自然語言或鏡頭導向的指令,自動規劃多個鏡頭與畫面段落,在無需手動剪輯的情況下,維持角色、風格與故事脈絡的一致性。 - 高品質長時影片輸出
支援長達 15 秒鐘的 1080P 影片生成,在畫面細節、動態流暢度與整體美術表現上皆有提升,適用於行銷、品牌內容與專業影音應用。
阿里雲 Wan 2.6官方宣傳影片
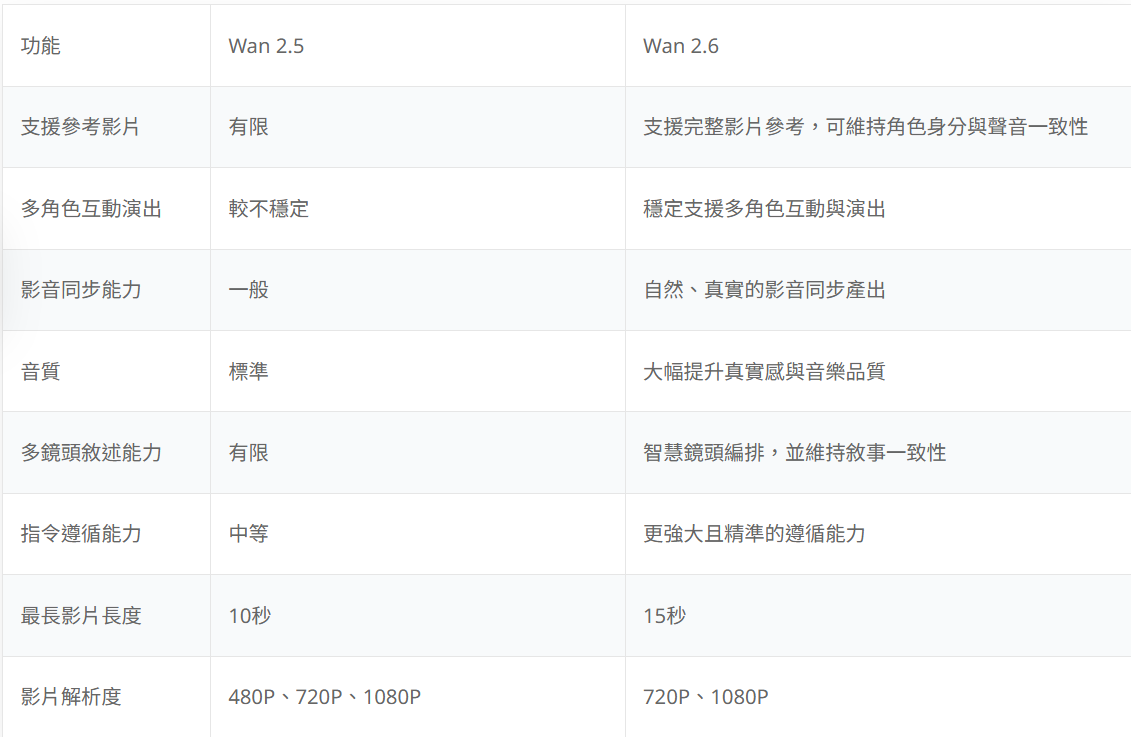
Wan 2.5 與 Wan2.6 的主要差別
通義萬相,為企業拓展AI視覺新饗宴
整體來看,通義萬相並非單一模型或單點功能,而是一套包含圖片生成、圖片編輯與影片生成的完整視覺生成能力體系。透過持續的模型演進與能力整合,通義萬相正逐步將生成式 AI 從輔助創作工具,推進為能實際支撐企業內容製作流程的核心技術。隨著最新版本 Wan 2.6 的推出,通義萬相在穩定性、一致性與影音品質等關鍵面向已達到更成熟的水準,進一步驗證其在企業視覺應用場景中的可行性與實用性。這也使企業能更安心地將 AI 視覺生成導入行銷、品牌、多媒體內容與內部溝通等實際應用中。
身為阿里雲專業合作夥伴,宏庭科技擁有豐富的阿里雲服務經驗,結合阿里雲強大的產品能力及技術支援,從需求評估、技術規劃到環境建置皆可提供完整支援,確保您的專案能獲得最高品質的支援與維護,從而專注於業務創新。
立即聯繫宏庭科技,獲取通義萬相專業諮詢


