
在先前的通義家族文章中,我們已帶領大家從整體架構的角度,理解阿里雲如何以多層次模型與平台服務,建構完整的企業級 AI 產品體系。從本文開始,將進一步聚焦通義家族的基礎大模型——通義千問,說明這個支撐整個通義家族運作的智慧核心,如何在競爭激烈的 AI 市場中持續進化,並協助企業更實際、也更安心地導入生成式 AI。
目錄
目錄
家族中的理性大腦:用文字理解世界
如同人類在面對複雜問題時,大腦需要對事件進行理性分析、資訊評估與邏輯推導來形成結論,企業級 AI 亦必須具備穩定且可預期的思考核心。在阿里雲的通義家族中,負責承接文字資訊、拆解問題結構,並將零散資料轉化為可執行判斷的智慧基礎,正是家族中的理性大腦 – 通義千問。
這樣的「理性大腦」角色,對企業而言尤為關鍵。當 AI 被引入正式營運流程後,其輸出的每一個判斷、建議與回應,都可能影響決策效率、服務品質,甚至風險控管。通義千問的存在,正是為了確保在多樣化 AI 應用之上,仍有一個能維持邏輯一致性與思考穩定度的核心支點。
通義千問模型三大核心亮點
目前通義千問已正式邁入第三代 – Qwen3,相較於前幾代的模型,第三代通義千問的演進方向已明確聚焦於「企業實際可用性」,並透過多項關鍵能力強化,回應企業在正式導入生成式 AI 時的核心需求。
- 整合推理與非推理的雙思維模式
Qwen3 系列模型原生整合「推理」(用於複雜的邏輯推理、數學和編碼)與「非推理」(用於快速高效的對話)模式,並可支援在單一模型內進行無縫切換。企業可依不同任務需求,在同一對話流程中彈性切換,兼顧推理品質、回應速度與成本效率。 - 強化 Agent 與工具協作能力
Qwen3 可更有效地與工具與流程整合,支援自動化任務執行與多步驟工作流程,讓 AI 從輔助角色進一步參與實際業務流程。 - 成熟的多語言理解與推理表現
支援超過百種語言與方言,在理解、翻譯與推理表現上具備極高的品質,適合跨區域、跨語系的企業應用場景。尤其擅長創意寫作、角色扮演、多輪對話和指令執行,從而提供更自然、更引人入勝、更沉浸式的對話體驗。
透過這些演進,Qwen3 已不再只是能力升級,而是逐步發展為可被企業納入正式營運流程、長期運作的核心智慧模型。
通義千問文本、視覺、語音的模型運用
除了模型的整體演進,為了讓企業能夠有效執行不同場景的操作,阿里雲針對不同業務場景發展出多種Qwen模型。透過上述設計,企業在導入生成式 AI 時,即可不必為了所有場景犧牲效能或成本,而是根據實際需求選擇最適合的模型。
文本模型-文字理解與推理的核心模型
此類模型是阿里雲通義千問中的重點核心,負責進行文本理解與邏輯推理。其主要分為三大類,差異主要在推理深度、回應速度與使用規模。
1. Qwen-Max:當 AI 需要進行多步驟思考、綜合大量資訊並產出高品質結論時,Qwen-Max 是最適合的選擇,他專為高複雜度推理與高一致性需求設計。
-
- 適用情境:適合企業在決策支援、跨部門資料分析、複雜流程判斷等情境中使用。
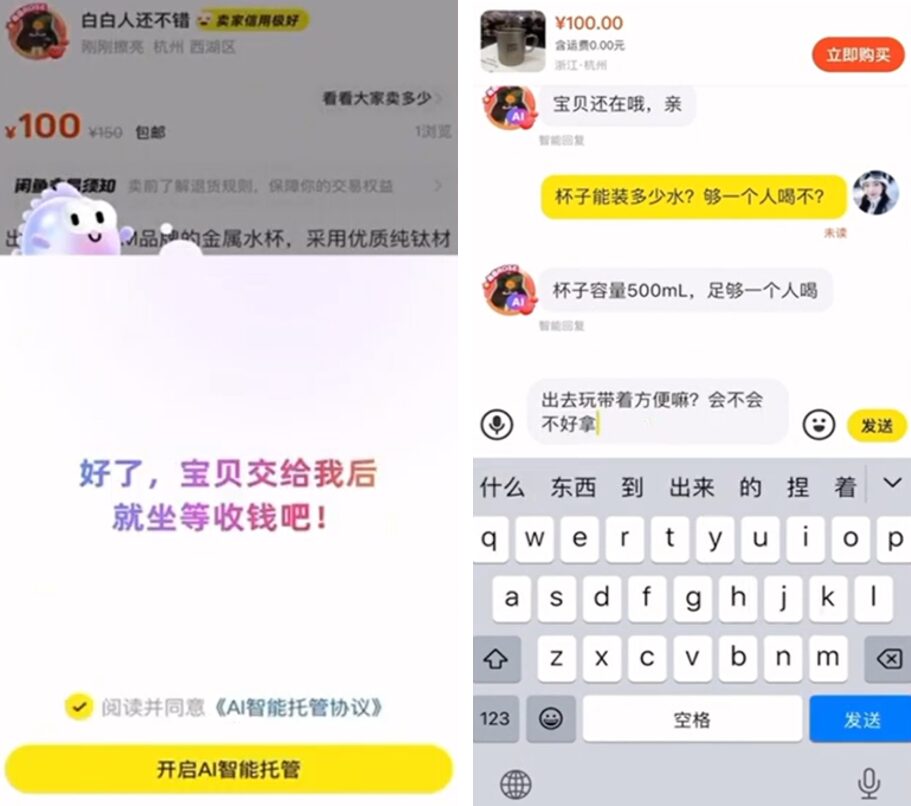
客服問答情境
2. Qwen-Plus:對於需要穩定輸出、且具備一定推理能力的應用,Qwen-Plus 是最具彈性的主力模型,其在推理能力與成本效益之間取得平衡,適合多數企業日常營運場景。
-
- 適用情境:內部知識問答、流程輔助、文件查詢與營運助理等。
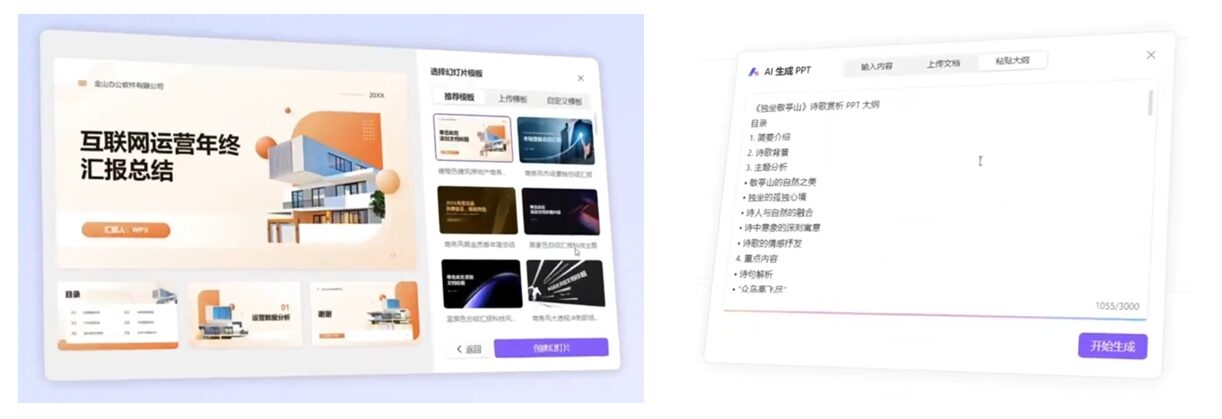
簡報快速製作

企業知識庫
3. Qwen-Flash:在追求回應速度與成本控制的情況下,Qwen-Flash 能以較低資源消耗提供穩定服務,其以低延遲與高效率為設計重點,特別適合即時互動與高併發場景。
-
- 適用情境:客服問答、即時助理與大量請求處理。
視覺模型-結合文字與影像的多模態理解模型 Qwen-VL
Qwen-VL 特別適合應用於文件辨識、表單解析、影像內容理解、圖文資料等需使用到視覺分析的場景,讓企業能將原本需要人工處理的視覺資訊,轉化為可被系統理解與分析的結構化資料。
三大亮點
- 從「看懂圖片」進化為「理解場景並採取行動」
Qwen-VL 不僅能辨識影像內容,更能理解圖像中的物件、關係與情境,進一步支援任務判斷與行動決策。這讓模型不只是做視覺分析,而是能實際參與流程,例如操作介面、執行查詢或輔助任務完成。
- 高精緻的多模態理解,涵蓋文件、畫面與真實世界
Qwen-VL 在文件理解、場景辨識與 OCR 能力上全面升級,能同時處理圖像、文字與複雜視覺內容,包括表單、介面截圖、實體場景與多語系文件。
- 支援長上下文與視覺推理,應對複雜任務需求
Qwen-VL 支援超長上下文處理(高達256K Token),能結合大量文字與影像資訊進行綜合推理,適用於需要多步驟分析與完整脈絡理解的情境,而非僅做單點辨識。

情境式問答分析
語音模型—Qwen-ASR-Flash 與 Qwen-TTS-Flash 比較
強大的即時語音辨識模型 Qwen-ASR-Flash
Qwen3-ASR-Flash 能因應不同語言、口音與實際使用環境,維持穩定且可靠的語音品質。無論是在背景安靜的線上課程、會議場景,或是雜音較多的直播、客服等環境,皆能準確進行語音辨識。目前支援超過 20 種語言,對於需要跨國合作的團隊或提供國際化內容的創作者來說,特別適合需要跨語系溝通與國際合作的企業與內容創作者,協助將語音內容快速轉化為可分析、可運用的文字資訊,進一步提升溝通與作業效率。
*支援語言:中文(普通話、四川話、閩南語、江浙話、粵語)、英語、日語、德語、韓語、俄語、法語、葡萄牙語、阿拉伯語、義大利語、西班牙語、印地語、印尼語、泰語、土耳其語、烏克蘭語、越南語、丹麥語、菲律賓語、芬蘭語、冰島語、烏茲別克語、波蘭語、波斯語、瑞典語
三大亮點
- 高準確度、多語言語音識別,支援複雜實際環境
Qwen-ASR-Flash 是專為精準語音識別所設計的模型,能在多語言、多口音與真實環境中,維持穩定的辨識品質。模型支援包含中文、英文在內的多種語言與方言,並可處理口語、專有名詞與混合語言等複雜語音內容。
- 即時回應與高效率處理,適合高頻與大量語音應用
Qwen-ASR-Flash 以高效能與低延遲為核心設計,能在即時語音轉寫與大量請求情境下,維持穩定的處理效率。即使在長時間或環境高頻情況下使用,仍能提供一致的語音識別體驗。
- 強化噪音處理與多場景適應能力,提升實用性
針對實際應用中常見的背景噪音、多人對話與環境干擾,Qwen-ASR-Flash 在語音辨識流程中強化對噪音與情境的處理能力,使模型能在會議室、客服中心、戶外或通話錄音等多種場景中穩定運作。
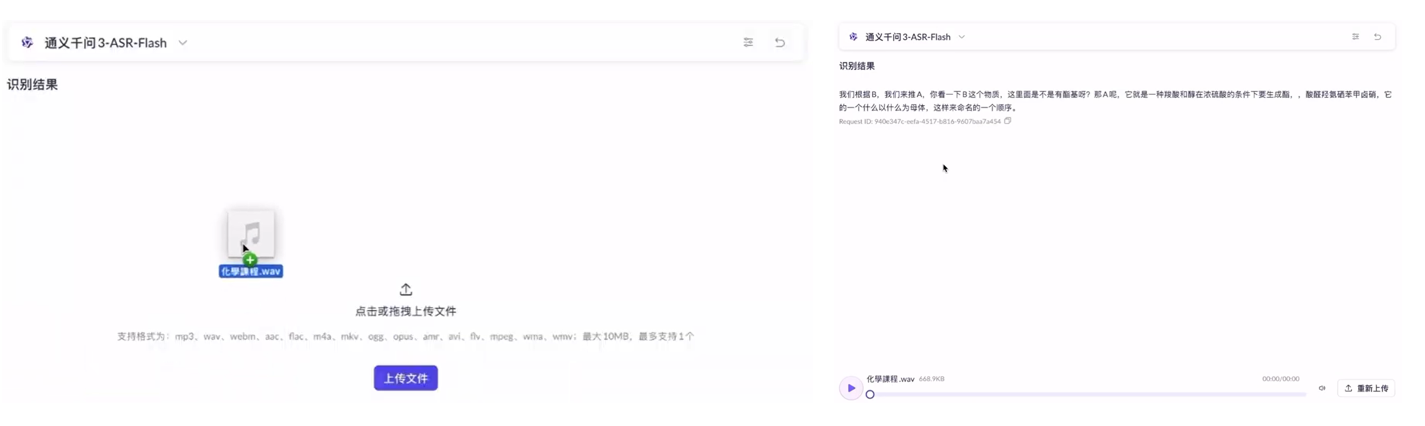
將音檔轉換成文字輸出
自然流暢語音生成模型 Qwen-TTS-Flash
Qwen-TTS-Flash 能將文字內容即時轉換為自然、清晰且易於理解的語音輸出,適用於多語言與多元應用情境。無論是即時客服、播報或語音助理等需要快速反應的場景,皆能提供穩定且流暢的語音體驗,協助企業打造更貼近使用者的互動服務。
三大亮點
- 自然流暢的語音生成
能將文字轉換為接近真人語感的語音輸出,減少機械感,讓互動更加自然。即使長時間播放,也能維持良好的聆聽體驗,適合實際對外服務應用。
- 即時回應與高效率穩定輸出
以低延遲與高效率為設計核心,能在大量請求或即時互動情境下,穩定進行語音輸出,確保服務不中斷。特別適合客服、即時助理與需要快速語音回應的應用場景。
- 多語言與多場景支援
支援多語言語音生成,可因應不同市場與應用需求,維持一致的語音品質。無論是企業客服、語音導覽,或跨語系服務情境,都能靈活應用並快速建置。
Meet the new Qwen3-TTS lineup: VoiceDesign & VoiceClone!
語音模型比較
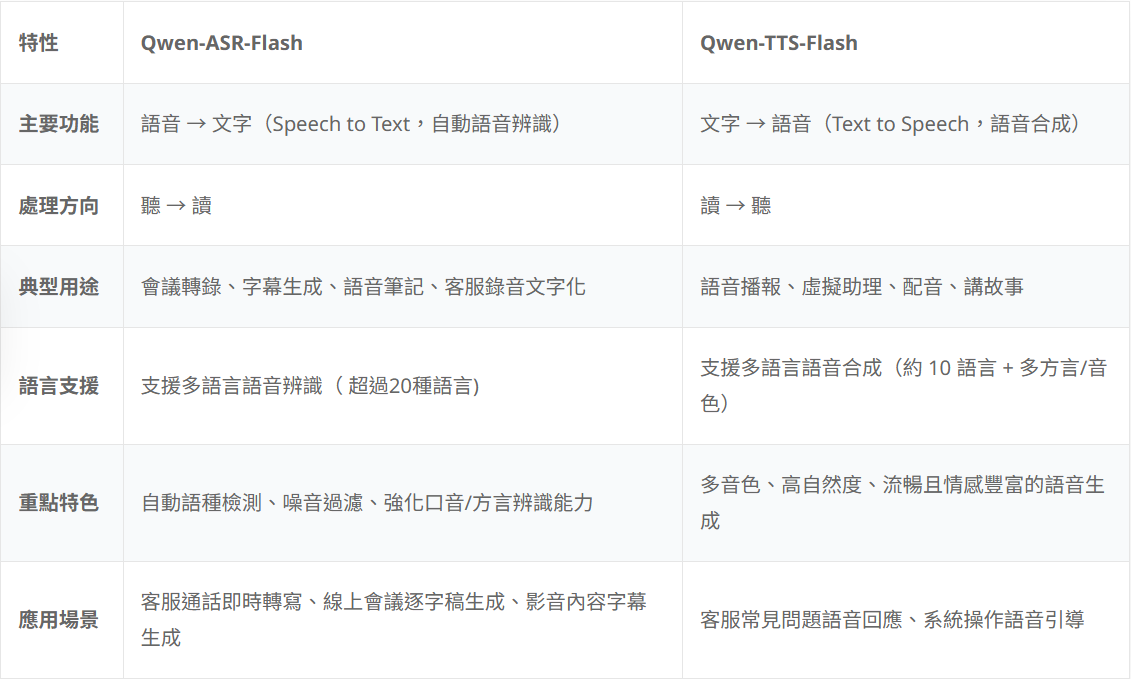
*此比較表格於 2026/01 製作
透過完整且清楚的模型分工,通義千問不再只是單一的大模型,而是一套能因應不同業務場景靈活組合的企業級 AI 模型體系。從文字理解與推理、多模態視覺與即時互動,到語音識別、語音生成與內容安全治理,企業可依實際需求選擇最合適的模型組合,在效能、成本與風險控管之間取得最佳平衡。然而,要發揮 AI 的 100% 實力,您需要一位懂技術、懂雲端、更懂產業應用的夥伴。
Microfusion 宏庭科技身為阿里雲精英等級的專業合作夥伴,長期深耕雲端服務領域,憑藉專業架構師團隊與原廠技術後盾,確保為企業打造穩健、安全、可擴展的雲端基礎,驅動業務創新、加速數位轉型。從模型挑選、架構搭建到資安防護,我們將協助您快速部署通義千問,將 AI 轉化為企業的真實競爭力。
立即聯繫宏庭科技,帶動您的智慧轉型!


